


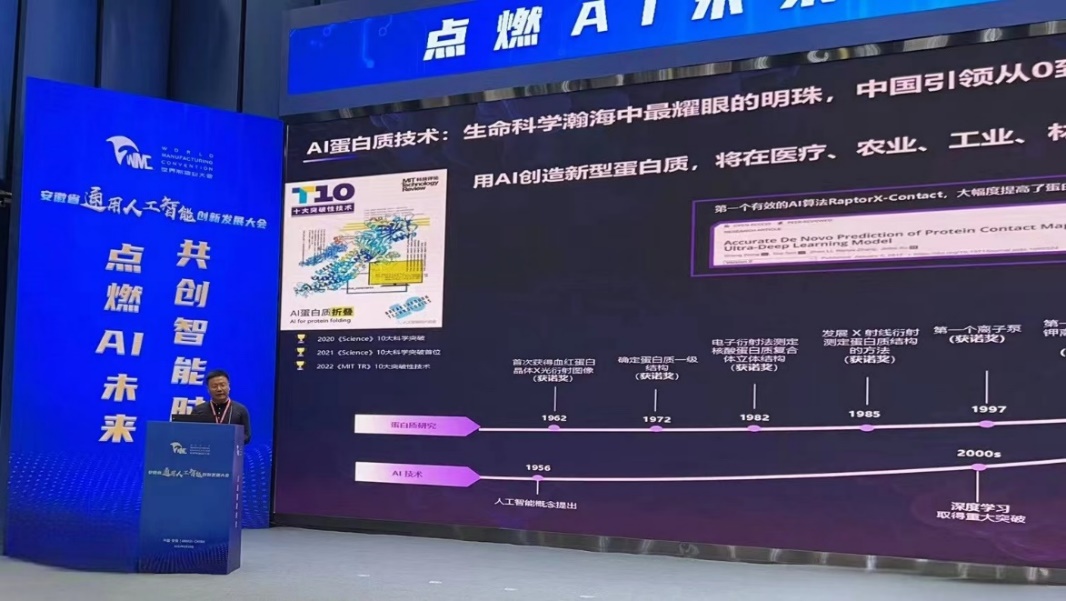
9月20日,工业和信息化部、国务院国资委、中国工程院、安徽省人民政府等共同主办的2023世界制造业大会在合肥召开,分子之心创始人、清华大学智能产业研究院(AIR)卓越访问教授许锦波教授携自主研发的全球首个AI蛋白质生成大模型NewOrigin(中文名“达尔文”)亮相。会上,汇聚各界人工智能领域高端人才、旨在推进多领域融合和协同创新的“AI百人会”成立,许锦波受聘任副会长。
许锦波介绍,NewOrigin大模型拥有百万级参数,学习了万亿级高质量、多层次、多模态的大数据,融合自然语言与蛋白语言,力图高精度、低门槛、高通用性地满足创新药设计、合成生物学等真实产业应用需求,大幅提升蛋白质设计的效率和成功率。NewOrigin大模型基于条件生成机制,联合使用AI、分子动力学、量子计算、湿实验等多维反馈机制,可高精度生成蛋白质序列、蛋白质功能、蛋白质知识表示等多种模态蛋白质内容,完成亲和力、稳定性、活性、表达量等多维度任务,满足真实的产业应用所需。而融合自然语言的交互方式,将极大降低使用门槛,让不具备AI算法能力的生物学家也可以快速上手。
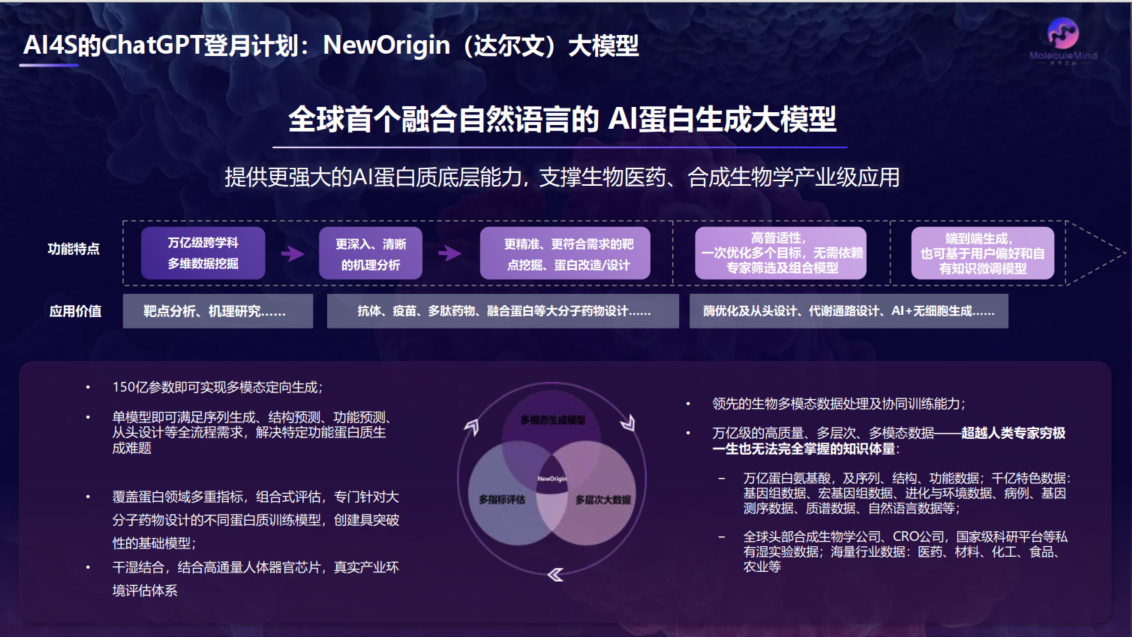
全球首个融合自然语言的AI蛋白质生成大模型NewOrigin(达尔文)
许锦波展示了NewOrigin大模型在药物设计领域的应用效果。
提升蛋白疫苗稳定性是提升蛋白质疫苗效果的重要途径之一。传统实验室方法通常使用饱和突变形成数千种、甚至数万种变体,从中筛选出符合需求的目标蛋白质,该过程耗费数月甚至数年,需要数百万成本。使用能量优化等传统计算方法受限于对能量变化的单一维度评估,精准度低,且耗时长、算力成本高。
“分子之心正与合作药企联合攻关,基于NewOrigin大模型解决蛋白疫苗稳定性难题。”许锦波透露。NewOrigin大模型可帮助药物研发团队快速分析,将提升蛋白疫苗效果的难题定位、拆解为可基于AI方法解决的子问题,如用AI设计突变提升蛋白疫苗的稳定性。而后,NewOrigin将对野生型蛋白进行突变设计,并自动调用语言模型、进化模型、结构模型、能量模型等一系列方法提取蛋白特征,预测蛋白疫苗突变体的各项性质,得到最理想的蛋白分子。仅需3天,NewOrigin就可设计出数十个理想的候选蛋白,经湿实验验证其中两个突变体性能超过了全球范围内公开已知的所有蛋白突变体,相对国际一线大药企最好的对照组结合能力最高提升4倍。
除了蛋白疫苗的稳定性优化,NewOrigin大模型也在亲和力优化、特异性优化、酶活性优化等多种传统方法难以突破的复杂问题上取得了重要进展。
这些蛋白质生成任务是当下通用大模型无法解决的难题。对ChatGPT的测试结果显示,它在蛋白质生成场景下无法生成符合需求的内容。

原因在于,蛋白质序列形成的结构比自然语言的结构复杂得多,蛋白质生成的应用场景多样且与自然语言交互的通用场景相差甚远,每一个需求的满足都需要“AI专家”与“生物专家”联合解决。另外,训练AI蛋白质生成大模型需要融合蛋白质数据、基因组数据、宏基因组数据、进化与环境数据、生物医学文献数据等多模态数据,这些数据的专业性、逻辑复杂性极高,且存在数据质控、数据冲突等难题,导致数据标注壁垒比通用NLP领域高数十倍。

AI蛋白质生成大模型的高专业门槛和以应用为目标的特点,要求其研发团队除了必备的算法、算力、数据等基础能力外,还需具备融合计算机、生物、物理等多学科,熟识AI、分子动力学、量子计算等多种方法的跨领域复合背景,以及真实的产业需求与验证能力。分子之心瞄准这一目标,搭建了一支融合AI生物交叉背景与深厚产业背景的复合型团队。这支超配团队正在基于万亿级海量数据持续生产高质量标注样本,开发泛化能力强的监督模型,通过主动学习算法持续迭代数据与专业知识,并通过多阶段预训练及基于相关性的多任务微调,驱动大模型不断学习迭代,提升蛋白质生成效果,满足药物设计、新材料设计、工业、农业、环保等不同领域的差异化蛋白质生成需求。
生物是一个高度复杂但又高度数字化的系统,具备可解读、可编程的特性,与AI大模型的特质高度匹配。许锦波教授表示:“AI蛋白质生成大模型等生物大模型具有广阔的产业应用前景,分子之心希望通过NewOrigin大模型变革生物医药与合成生物学的未来,帮助人们平等地获取可负担的高品质生物药及绿色生物产品。”




请输入验证码